PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•( дәҢ )
зәөи§Ӯзӣ®еүҚе…¬ејҖзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢжҲ‘们еҸҜд»ҘеҸ‘зҺ°пјҢRoBERTa жҳҜе…¶дёӯдёҖдёӘж•ҲжһңйқһеёёеҘҪзҡ„и¶…ејәеҹәеҮҶжЁЎеһӢгҖӮиҝҷеҸҘиҜқжңүеҮ дёӘж„ҸжҖқпјҡ
йҰ–е…ҲпјҢе°Ҫз®ЎзңӢдёҠеҺ» RoBERTa д№ҹжІЎеҒҡе•ҘжҠҖжңҜжҲ–иҖ…жЁЎеһӢж”№иҝӣпјҢеҸӘжҳҜжҠҠ Bert жЁЎеһӢи®ӯз»ғеҫ—жӣҙе……еҲҶдәҶдёҖдәӣпјҢдҪҶжҳҜпјҢе®ғзҡ„ж•ҲжһңжҳҜйқһеёёеҘҪзҡ„гҖӮзӣ®еүҚдёәжӯўпјҢж•ҲжһңиғҪеӨҹжҳҺжҳҫи¶…иҝҮе®ғзҡ„жЁЎеһӢеҫҲе°‘пјҢеұҲжҢҮеҸҜж•°пјҢиҝҷдёӘ"еұҲжҢҮеҸҜж•°"пјҢдёҚжҳҜиҷҡжҢҮпјҢжҳҜе®ғзҡ„еӯ—йқўеҗ«д№үгҖӮиҝҷдёӘдәӢе®һпјҢе…¶е®һйҡҗеҗ«дәҶеҫҲеӨ§зҡ„дҝЎжҒҜйҮҸпјҢе®ғиҜҙжҳҺдәҶдёҖдёӘд»Җд№Ҳй—®йўҳе‘ўпјҹжӮЁеҸҜд»ҘжғідёҖжғіпјҢжҲ‘зҡ„зңӢжі•еңЁеҗҺйқўе°ҸиҠӮеҶ…е®№дјҡжҸҗеҲ°гҖӮ
е…¶ж¬ЎпјҢеҜ№дәҺдёҖдёӘж”№иҝӣжЁЎеһӢжқҘиҜҙпјҢзҗҶи®әдёҠйғҪеә”иҜҘеј•е…Ҙ RoBERTa дҪңдёәеҜ№жҜ” BaselineпјҢиҖҢж”№иҝӣжЁЎеһӢзҡ„ж•ҲжһңпјҢеҰӮжһңдёҚиғҪе…·еӨҮиҜҙжңҚеҠӣең°и¶…иҝҮ RoBERTa зҡ„иҜқпјҢйӮЈд№Ҳиҝҷз§Қж”№иҝӣзҡ„жңүж•ҲжҖ§пјҢеӨҡе°‘жҳҜжҲҗй—®йўҳзҡ„пјҢйҷӨйқһдҪ ејәи°ғж”№иҝӣжЁЎеһӢзҡ„дјҳеҠҝдёҚеңЁж•ҲжһңеҘҪпјҢиҖҢеңЁе…¶е®ғж–№йқўпјҢжҜ”еҰӮжӣҙе°Ҹжӣҙеҝ«зӯүгҖӮ
еҶҚж¬ЎпјҢеҗҺз»ӯзҡ„ж”№иҝӣйў„и®ӯз»ғжЁЎеһӢпјҢд»Һзӯ–з•Ҙи§’еәҰи®ІпјҢеә”иҜҘеңЁи®ҫи®Ўд№ӢеҲқпјҢе°ұз«ҷеңЁ RoBERTa зҡ„е·ЁдәәиӮ©иҶҖдёҠпјҢе°ұжҳҜиҜҙеңЁеўһеҠ дёҖе®ҡж•°жҚ®йҮҸзҡ„еүҚжҸҗдёӢпјҢеўһеӨ§ Batch SizeпјҢеҠ й•ҝйў„и®ӯз»ғж—¶й—ҙпјҢи®©жЁЎеһӢеҫ—еҲ°е……еҲҶи®ӯз»ғгҖӮеӣ дёәпјҢеҰӮжһңдҪ дёҚиҝҷд№ҲеҒҡпјҢеӨ§жҰӮзҺҮдҪ зҡ„ж•ҲжһңжҳҜеҫҲйҡҫжҜ”иҝҮ RoBERTa зҡ„пјҢиҖҢзӣ®еүҚжҲ‘们иғҪеӨҹи§ҒеҲ°зҡ„ж•ҲжһңеҫҲзӘҒеҮәзҡ„жЁЎеһӢпјҢдҪ еҰӮжһңз»Ҷ究пјҢдјҡеҸ‘зҺ°е…¶е®һйғҪе·Із»Ҹеј•е…ҘдәҶ RoBERTa зҡ„е…ій”®иҰҒзҙ дәҶпјҢе…ідәҺиҝҷдёҖзӮ№пјҢеңЁеҗҺйқўе°ҸиҠӮжҲ‘们дјҡеҒҡеҲҶжһҗгҖӮ
иҝҳжңүпјҢеҜ№дәҺиҝҪжұӮиҗҪең°ж•Ҳжһңзҡ„дәәжқҘиҜҙпјҢжҜ”еҰӮе…¬еҸёйҮҢеҒҡдёҡеҠЎзҡ„еҗҢеӯҰпјҢе»әи®®д»Ҙ RoBERTa дёәеҹәзЎҖжЁЎеһӢжқҘеҒҡеә”з”ЁгҖӮ
йў„и®ӯз»ғзҡ„еҸ‘еҠЁжңәпјҡжЁЎеһӢз»“жһ„
еҜ№дәҺйў„и®ӯз»ғжЁЎеһӢжқҘиҜҙпјҢзӣ®еүҚзҡ„дё»жөҒжЁЎеһӢеӨ§йғҪйҮҮз”Ё Transformer дҪңдёәзү№еҫҒжҠҪеҸ–еҷЁпјҢзҺ°йҳ¶ж®өзңӢпјҢTransformer зҡ„жҪңеҠӣд»Қ然没жңүиў«е……еҲҶжҢ–жҺҳпјҢиҝҳжңүеҫҲеӨ§жҪңеҠӣеҸҜжҢ–пјҢж„ҸжҖқжҳҜпјҢTransformer ж•Ҳжһңи¶іеӨҹеҘҪпјҢиҖҢдё”иҝҳеҸҜд»ҘжӣҙеҘҪпјҢиІҢдјјж”№иҝӣ Transformer 并йқһеҪ“еҠЎд№ӢжҖҘзҡ„дәӢжғ…гҖӮйў„и®ӯз»ғжЁЎеһӢзҡ„зҹҘиҜҶпјҢжҳҜйҖҡиҝҮ Transformer еңЁи®ӯз»ғиҝӯд»Јдёӯд»Һж•°жҚ®дёӯдёҚж–ӯеӯҰд№ пјҢ并д»ҘжЁЎеһӢеҸӮж•°зҡ„еҪўејҸзј–з ҒеҲ°жЁЎеһӢдёӯзҡ„гҖӮиҷҪ然пјҢеӨ§е®¶йғҪжҳҜз”Ёзҡ„ TransformerпјҢдҪҶжҳҜжҖҺд№Ҳз”Ёе®ғжҗӯе»әжЁЎеһӢз»“жһ„еӯҰд№ ж•ҲзҺҮжӣҙй«ҳпјҹиҝҷжҳҜдёҖдёӘй—®йўҳгҖӮжүҖи°“еӯҰд№ ж•ҲзҺҮй«ҳпјҢе°ұжҳҜз»ҷе®ҡзӣёеҗҢеӨ§е°Ҹ规模зҡ„и®ӯз»ғж•°жҚ®пјҢе®ғиғҪзј–з ҒжӣҙеӨҡзҡ„зҹҘиҜҶеҲ°жЁЎеһӢйҮҢпјҢиҝҷе°ұж„Ҹе‘ізқҖе®ғзҡ„еӯҰд№ ж•ҲзҺҮжӣҙй«ҳгҖӮдёҚеҗҢзҡ„ Transformer з”Ёжі•пјҢдјҡдә§з”ҹдёҚеҗҢзҡ„жЁЎеһӢз»“жһ„пјҢе°ұдјҡеҜјиҮҙдёҚеҗҢз»“жһ„зҡ„е·®ејӮеҢ–зҡ„еӯҰд№ ж•ҲзҺҮгҖӮ
жң¬иҠӮжҲ‘们еҪ’зәідёӢзӣ®еүҚиғҪеҫ—еҲ°зҡ„пјҢе…ідәҺжЁЎеһӢз»“жһ„зҡ„зҺ°жңүз ”з©¶з»“и®әпјҢдјҡд»Ӣз»Қеёёи§Ғзҡ„дә”з§ҚжЁЎеһӢз»“жһ„гҖӮеҪ“然пјҢиҝҷйҮҢз”ЁжЁЎеһӢз»“жһ„жқҘиЎЁиҫҫдёҚи¶іеӨҹзЎ®еҲҮпјҢеӣ дёәйҷӨдәҶжЁЎеһӢз»“жһ„еӨ–пјҢдёҖиҲ¬иҝҳеҢ…еҗ«иҮӘзӣ‘зқЈзҡ„еӯҰд№ ж–№жі•пјҢеёёи§Ғзҡ„еӯҰд№ ж–№жі•еҢ…жӢ¬ AutoEncoding(з®Җз§° AE)е’Ң AutoRegressive(з®Җз§° AR)гҖӮAE еҚіжҲ‘们常иҜҙзҡ„еҸҢеҗ‘иҜӯиЁҖжЁЎеһӢпјҢиҖҢ AR еҲҷд»ЈиЎЁд»Һе·ҰеҲ°еҸізҡ„еҚ•еҗ‘иҜӯиЁҖжЁЎеһӢгҖӮ
Encoder-AE з»“жһ„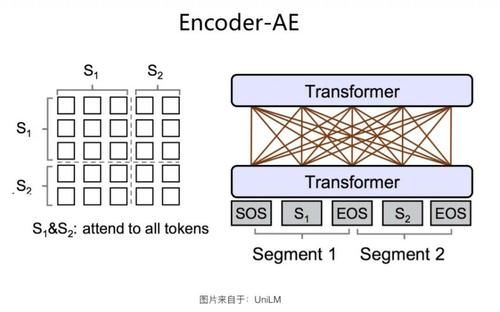
ж–Үз« еӣҫзүҮ
Encoder-AE з»“жһ„еҰӮдёҠеӣҫжүҖзӨәгҖӮиҝҷе…¶е®һжҳҜеҢ…жӢ¬еҺҹе§ӢзүҲжң¬ Bert еңЁеҶ…зҡ„пјҢеӨ§еӨҡж•°еҗҺз»ӯж”№иҝӣжЁЎеһӢйҮҮеҸ–зҡ„з»“жһ„гҖӮж•ҙдёӘз»“жһ„е°ұжҳҜдёҖдёӘж ҮеҮҶзҡ„ TransformerпјҢеңЁиҜӯиЁҖжЁЎеһӢйў„и®ӯз»ғзҡ„ж—¶еҖҷпјҢйҮҮз”Ё AE ж–№жі•гҖӮд№ҹе°ұжҳҜиҜҙпјҢиҫ“е…ҘеҸҘдёӯзҡ„жңӘиў« Mask зҡ„д»»ж„ҸеҚ•иҜҚдёӨдёӨеҸҜи§ҒпјҢдҪҶжҳҜиў« Mask жҺүзҡ„еҚ•иҜҚд№Ӣй—ҙйғҪзӣёдә’зӢ¬з«ӢпјҢдә’дёҚеҸҜи§ҒгҖӮеңЁйў„жөӢжҹҗдёӘиў« Mask жҺүзҡ„еҚ•иҜҚзҡ„ж—¶еҖҷпјҢжүҖжңүе…¶е®ғиў« Mask зҡ„еҚ•иҜҚйғҪдёҚиө·дҪңз”ЁпјҢдҪҶжҳҜеҸҘеҶ…жңӘиў« Mask жҺүзҡ„жүҖжңүеҚ•иҜҚпјҢйғҪеҸҜд»ҘеҸӮдёҺеҪ“еүҚеҚ•иҜҚзҡ„йў„жөӢгҖӮеҸҜд»ҘзңӢеҮәпјҢEncoder-AE жҳҜдёӘйҮҮз”ЁеҸҢеҗ‘иҜӯиЁҖжЁЎеһӢзҡ„еҚ• Transformer з»“жһ„гҖӮ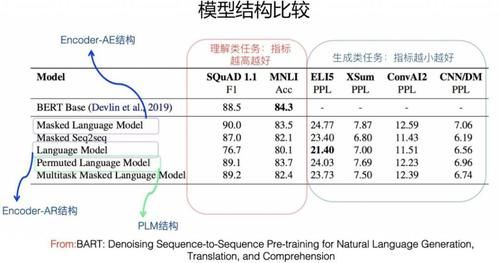
ж–Үз« еӣҫзүҮ
жЁЎеһӢз»“жһ„жҜ”иҫғпјҲFrom BARTпјү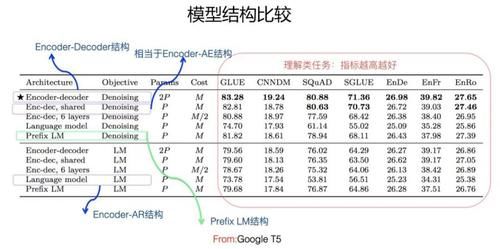
ж–Үз« еӣҫзүҮ
жЁЎеһӢз»“жһ„жҜ”иҫғпјҲFrom Google T5пјүд»Һзӣ®еүҚеҜ№жҜ”е®һйӘҢзңӢпјҲдёҠйқўдёӨеӣҫпјүпјҢйҷӨдәҶдёӢж–ҮиҰҒи®Іиҝ°зҡ„ Encoder-Decoder з»“жһ„еӨ–пјҢиІҢдјјеҜ№дәҺиҜӯиЁҖзҗҶи§Јзұ»зҡ„ NLP д»»еҠЎпјҢиҝҷз§Қз»“жһ„йғҪжҳҜж•ҲжһңжңҖеҘҪзҡ„пјҢдҪҶжҳҜеҜ№дәҺиҜӯиЁҖз”ҹжҲҗзұ»зҡ„д»»еҠЎпјҢиҝҷз§Қз»“жһ„ж•ҲжһңзӣёеҜ№еҫҲе·®гҖӮд№ҹе°ұжҳҜиҜҙпјҢиҝҷз§Қз»“жһ„жҜ”иҫғйҖӮеҗҲеҒҡиҜӯиЁҖзҗҶи§Јзұ»зҡ„д»»еҠЎгҖӮ
Decoder-AR з»“жһ„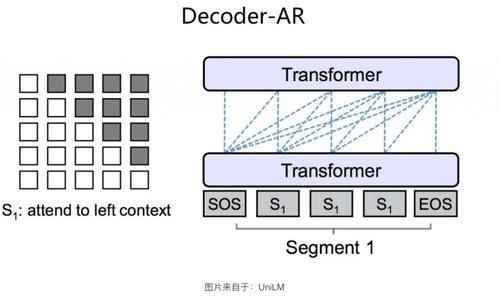
ж–Үз« еӣҫзүҮ
Decoder-AR з»“жһ„еҰӮдёҠеӣҫжүҖзӨәгҖӮ е®ғе’Ң Encoder-AE з»“жһ„зӣёеҗҢпјҢйғҪжҳҜйҮҮз”ЁеҚ•дёӘзҡ„ж ҮеҮҶ TransformerпјҢдё»иҰҒеҢәеҲ«еңЁдәҺпјҡиҜӯиЁҖжЁЎеһӢйў„и®ӯз»ғзҡ„ж—¶еҖҷпјҢйҮҮз”Ё AR ж–№жі•пјҢе°ұжҳҜд»Һе·ҰеҲ°еҸійҖҗдёӘз”ҹжҲҗеҚ•иҜҚпјҢ第 i дёӘеҚ•иҜҚ [е…¬ејҸ] еҸӘиғҪзңӢеҲ°е®ғд№ӢеүҚзҡ„第 1 еҲ°з¬¬пјҲi-1пјүдёӘеҚ•иҜҚ [е…¬ејҸ] пјҢдёҚиғҪзңӢеҲ°еҗҺйқўзҡ„еҚ•иҜҚгҖӮйҮҮз”Ёиҝҷз§Қз»“жһ„зҡ„е…ёеһӢжЁЎеһӢе°ұжҳҜ GPT1гҖҒGPT2гҖҒGPT3 зі»еҲ—дәҶгҖӮGPT3 еңЁж–Үжң¬з”ҹжҲҗд»»еҠЎж–№йқўзҡ„иЎЁзҺ°пјҢзЎ®е®һжҳҜеҮәд№Һж„Ҹж–ҷең°еҘҪгҖӮеҪ“然пјҢиҝҷдёҚиғҪд»…д»…еҪ’еҠҹдәҺиҝҷдёӘз»“жһ„жң¬иә«пјҢжӣҙеӨҚжқӮзҡ„жЁЎеһӢе’ҢжӣҙеӨ§йҮҸзҡ„ж•°жҚ®еҸҜиғҪжҳҜдё»еӣ гҖӮеҸҜд»ҘзңӢеҮәпјҢDecoder-AR з»“жһ„жҳҜдёӘеҚ•еҗ‘иҜӯиЁҖжЁЎеһӢзҡ„еҚ• Transformer з»“жһ„гҖӮд»Һзӣ®еүҚеҜ№жҜ”е®һйӘҢзңӢпјҲеҸӮиҖғ Encoder-AE е°ҸиҠӮзҡ„дёӨеј ж•ҲжһңеҜ№жҜ”еӣҫпјүпјҢйҷӨдәҶ Encoder-Decoder з»“жһ„еӨ–пјҢиІҢдјјеҜ№дәҺиҜӯиЁҖз”ҹжҲҗзұ»зҡ„д»»еҠЎпјҢиҝҷз§Қз»“жһ„жҳҜж•ҲжһңжңҖеҘҪзҡ„з»“жһ„д№ӢдёҖгҖӮдҪҶжҳҜзӣёеә”зҡ„пјҢиҜӯиЁҖзҗҶи§Јзұ»зҡ„д»»еҠЎпјҢйҮҮз”Ёиҝҷз§Қз»“жһ„пјҢж•ҲжһңжҜ” Encoder-AE з»“жһ„е·®и·қйқһеёёжҳҺжҳҫпјҢиҝҷд№ҹеҘҪзҗҶи§ЈпјҢеӣ дёәеҸӘзңӢеҲ°дёҠж–ҮзңӢдёҚеҲ°дёӢж–ҮпјҢеҜ№дәҺеҫҲеӨҡиҜӯиЁҖзҗҶи§Јзұ»д»»еҠЎиҖҢиЁҖпјҢдҝЎжҒҜжҚҹеӨұеҫҲеӨ§пјҢжүҖд»Ҙж•ҲжһңдёҚеҘҪд№ҹеңЁжғ…зҗҶд№ӢдёӯгҖӮд№ҹе°ұжҳҜиҜҙпјҢиҝҷз§Қз»“жһ„жҜ”иҫғйҖӮеҗҲеҒҡиҜӯиЁҖз”ҹжҲҗзұ»зҡ„д»»еҠЎгҖӮ
Encoder-Decoder з»“жһ„
既然 Encoder-AE жҜ”иҫғйҖӮеҗҲеҒҡиҜӯиЁҖзҗҶи§Јзұ»зҡ„д»»еҠЎпјҢEncoder-AR жҜ”иҫғйҖӮеҗҲеҒҡиҜӯиЁҖз”ҹжҲҗзұ»зҡ„д»»еҠЎгҖӮйӮЈд№ҲпјҢжҲ‘们иғҪеҗҰз»“еҗҲдёӨиҖ…зҡ„дјҳеҠҝпјҢдҪҝеҫ—йў„и®ӯз»ғжЁЎеһӢж—ўиғҪеҒҡеҘҪз”ҹжҲҗзұ» NLP д»»еҠЎпјҢеҸҲиғҪеҒҡеҘҪзҗҶи§Јзұ»д»»еҠЎе‘ўпјҹиҝҷжҳҜдёӘеҫҲиҮӘ然зҡ„жғіжі•пјҢиҖҢ Encoder-Decoder з»“жһ„е°ұжҳҜеҰӮжӯӨе°ҶдёӨиҖ…з»“еҗҲзҡ„гҖӮжңҖж—©жҳҺзЎ®жҸҗеҮәдҪҝз”Ё Encoder-Decoder з»“жһ„еҒҡйҖҡз”ЁйўҶеҹҹйў„и®ӯз»ғзҡ„пјҢеә”иҜҘжҳҜеҫ®иҪҜжҸҗеҮәзҡ„ MASS жЁЎеһӢпјҢдёҚиҝҮе’ҢиҝҷйҮҢд»Ӣз»Қзҡ„еҒҡжі•жңүе·®ејӮгҖӮ
жҺЁиҚҗйҳ…иҜ»


















- йҳҹеҸӢ|жІҲжўҰиҫ°жӣқе…үйҳҹеҸӢвҖңдё‘з…§вҖқпјҢдҪҶжҳҫзӨәеҮәиүҜеҘҪзҡ„дәәж°”
- е…¬жј”|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢ第дә”ж¬Ўе…¬жј”зҺ°еңәпјҢжқҺж–Ҝдё№еҰ®з»„гҖҠжғ…дәәгҖӢеӨӘжғҠиүі
- зјәдҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- ж—¶е°ҡзӢӮжғіжӣІ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еҲ¶еӣўз»јпјҢеј йӣЁз»®з«ҷпјЈдҪҚпјҢз®ҖзәҰиЎ¬иЎЈзҪ•и§Ғз§ҖзҹҘжҖ§
- еҪ’дҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- 10жңҲ|еҚ°еәҰеҸ‘з”ҹ5.1зә§ең°йңҮпјҢйңҮжәҗж·ұеәҰ40еҚғзұі
- йҷҲиө«|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢжҲҗеӣўеӨңиҜ·дәҶ17дҪҚз”·еҳүе®ҫпјҢйҷҲиө«жғ№жқҘдёҖзүҮдәүи®®
- иҠӮзӣ®з»„|еӯҹдҪіпјҢеҲ«жҢЈжүҺдәҶпјҢгҖҠд№ҳйЈҺз ҙжөӘгҖӢиҠӮзӣ®з»„жҳҺж‘ҶзқҖжғіжҠҠдҪ ж·ҳжұ°
- е®Ғйқҷ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еӣўз»јпјҢе®ҒйқҷдёҮиҢңз ҙдёҚе’Ңдј й—»пјҢи·Ҝжј”и§Ҷйў‘ж¬ўд№җеӨҡ
- ж¶ҲжҒҜиө„и®Ҝ|д№ҳйЈҺз ҙжөӘ | еҸҳйқ©иҪ¬еһӢпјҡдәәжүҚеҹ№е…»вҖ”вҖ”дјҒдёҡиҪ¬еһӢдёҺеҲӣж–°зҡ„ж ёеҝғй©ұеҠЁеҠӣ