PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•( дёү )
ж–Үз« еӣҫзүҮ
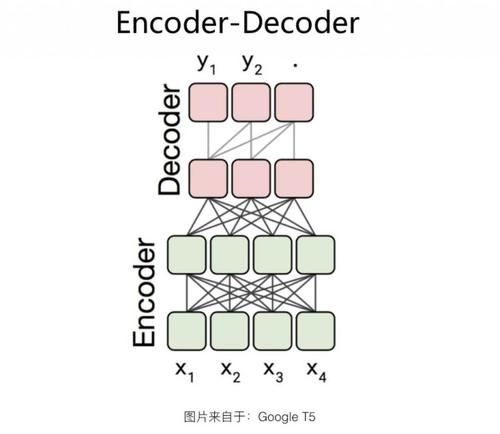
Encoder-Decoder з»“жһ„еҰӮдёҠеӣҫжүҖзӨәгҖӮ иҝҷз§Қз»“жһ„еңЁ Encoder дҫ§пјҢеҚ•зӢ¬дҪҝз”ЁдёҖдёӘ TransformerпјҢйҮҮз”ЁдәҶ Encoder-AE зҡ„з»“жһ„гҖӮд№ҹе°ұжҳҜиҜҙпјҢзј–з Ғйҳ¶ж®өйҮҮз”ЁеҸҢеҗ‘иҜӯиЁҖжЁЎеһӢпјҢд»»ж„ҸдёӨдёӘеҚ•иҜҚдёӨдёӨеҸҜи§ҒпјҢд»Ҙжӣҙе……еҲҶең°зј–з Ғиҫ“е…ҘдҝЎжҒҜпјӣиҖҢеңЁ Decoder дҫ§пјҢдҪҝз”ЁеҸҰеӨ–дёҖдёӘ TransformerпјҢйҮҮз”ЁдәҶ Decoder-AR з»“жһ„пјҢд»Һе·ҰеҲ°еҸійҖҗдёӘз”ҹжҲҗеҚ•иҜҚгҖӮеҪ“然пјҢDecoder дҫ§е’Ңж ҮеҮҶзҡ„ Decoder-AR дёҚеҗҢзҡ„ең°ж–№иҝҳжҳҜжңүзҡ„пјҡDecoder дҫ§з”ҹжҲҗзҡ„еҚ•иҜҚ [е…¬ејҸ] пјҢйҷӨдәҶеғҸ Decoder-AR з»“жһ„дёҖж ·иғҪзңӢеҲ°еңЁе®ғд№ӢеүҚз”ҹжҲҗзҡ„еҚ•иҜҚеәҸеҲ— [е…¬ејҸ] еӨ–пјҢиҝҳиғҪзңӢеҲ° Encoder дҫ§зҡ„жүҖжңүиҫ“е…ҘеҚ•иҜҚ гҖӮиҖҢиҝҷдёҖиҲ¬жҳҜйҖҡиҝҮ Decoder дҫ§еҜ№ Encoder дҫ§еҚ•иҜҚпјҢиҝӣиЎҢ Attention ж“ҚдҪңж–№ејҸжқҘе®һзҺ°зҡ„пјҢиҝҷз§Қ Attention дёҖиҲ¬ж”ҫеңЁ Encoder йЎ¶еұӮ Transformer Block зҡ„иҫ“еҮәдёҠгҖӮ
еңЁиҝӣиЎҢйў„и®ӯз»ғзҡ„ж—¶еҖҷпјҢEncoder е’Ң Decoder дјҡеҗҢж—¶еҜ№дёҚеҗҢ Mask йғЁеҲҶиҝӣиЎҢйў„жөӢпјҡEncoder дҫ§еҸҢеҗ‘иҜӯиЁҖжЁЎеһӢз”ҹжҲҗиў«йҡҸжңә Mask жҺүзҡ„йғЁеҲҶеҚ•иҜҚпјӣDecoder дҫ§еҚ•еҗ‘иҜӯиЁҖжЁЎеһӢд»Һе·ҰеҲ°еҸіз”ҹжҲҗиў« Mask жҺүзҡ„дёҖйғЁеҲҶиҝһз»ӯзүҮж–ӯгҖӮдёӨдёӘд»»еҠЎиҒ”еҗҲи®ӯз»ғпјҢиҝҷж · Encoder е’Ң Decoder дёӨдҫ§йғҪеҸҜд»Ҙеҫ—еҲ°жҜ”иҫғе……еҲҶең°и®ӯз»ғгҖӮ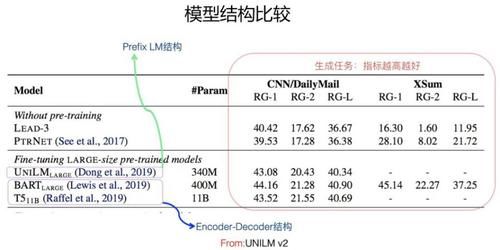
ж–Үз« еӣҫзүҮ
жЁЎеһӢз»“жһ„жҜ”иҫғпјҲFrom UniLM v2пјүд»Һзӣ®еүҚеҜ№жҜ”е®һйӘҢзңӢпјҢж— и®әжҳҜиҜӯиЁҖзҗҶи§Јзұ»зҡ„д»»еҠЎпјҲеҸӮиҖғ Encoder-AE йғЁеҲҶ Google T5 и®әж–Үдёӯеұ•зӨәзҡ„ж•ҲжһңеҜ№жҜ”еӣҫпјүпјҢиҝҳжҳҜиҜӯиЁҖз”ҹжҲҗзұ»зҡ„д»»еҠЎпјҲеҸӮиҖғдёҠйқўжқҘиҮӘдәҺ UniLM v2 зҡ„ж•ҲжһңеҜ№жҜ”пјүпјҢиІҢдјј Encoder-Decoder з»“жһ„зӣёеҜ№е…¶е®ғеҮ з§Қз»“жһ„жқҘиҜҙпјҢж•ҲжһңйғҪжҳҜжңҖеҘҪзҡ„д№ӢдёҖгҖӮиҖҢдё”пјҢе®ғжңүеҸҰеӨ–дёҖдёӘдјҳзӮ№пјҢе°ұжҳҜз”ЁиҝҷдёӘз»“жһ„пјҢеҸҜд»ҘеҗҢж—¶еҒҡз”ҹжҲҗзұ»е’ҢзҗҶи§Јзұ»зҡ„ NLP д»»еҠЎпјҢеҹәжң¬еҒҡеҲ°дәҶдёҚеҗҢд»»еҠЎеңЁжЁЎеһӢз»“жһ„дёҠзҡ„з»ҹдёҖпјҢиҝҷзӮ№иҝҳжҳҜеҫҲеҘҪзҡ„пјҢдёҖдёӘз»“жһ„еҸҜд»ҘеҲ°еӨ„дҪҝз”ЁпјҢжҜ”иҫғж–№дҫҝгҖӮдҪҶжҳҜпјҢе®ғд№ҹжңүдёӘй—®йўҳпјҢеӣ дёәдёӨдҫ§еҗ„з”ЁдәҶдёҖдёӘ TransformerпјҢжүҖд»ҘзӣёеҜ№е…¶е®ғз»“жһ„еҸӮж•°йҮҸзҝ»еҖҚпјҢи®Ўз®—йҮҸд№ҹеўһеҠ дәҶпјҢе°ұжҳҜиҜҙжҜ”е…¶е®ғжЁЎеһӢз¬ЁйҮҚгҖӮиҖҢдё”пјҢEncoder-Decoder з»“жһ„жҜ”е…¶е®ғз»“жһ„ж•ҲжһңеҘҪпјҢеҫҲеҸҜиғҪдё»иҰҒеҺҹеӣ жқҘиҮӘдәҺеҸӮж•°йҮҸеўһеҠ еҜјиҮҙзҡ„жЁЎеһӢе®№йҮҸеўһеӨ§пјҢеҪ“然иҝҷжҳҜдёӘдәәзҢңжөӢгҖӮзӣ®еүҚпјҢйҮҮз”ЁиҝҷдёӘз»“жһ„зҡ„ж•ҲжһңеҫҲеҘҪзҡ„жЁЎеһӢеҢ…жӢ¬ Google T5 д»ҘеҸҠ BART зӯүжЁЎеһӢгҖӮ
Prefix LM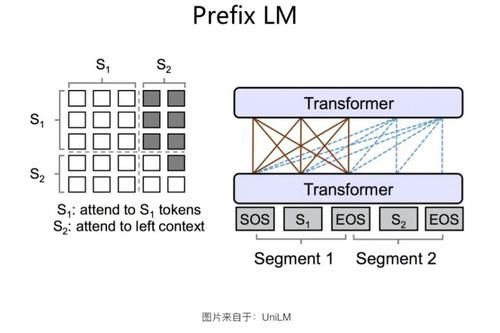
ж–Үз« еӣҫзүҮ
Prefix LM з»“жһ„жҳҜ Google T5 и®әж–Үдёӯз»ҷеҮәзҡ„еҸ«жі•пјҢиҝҷз§Қз»“жһ„жңҖж—©з”ұ UniLM жЁЎеһӢжҸҗеҮәпјҢжҲ‘们жІҝз”Ё Google T5 зҡ„иҝҷз§Қз§°и°“гҖӮеҰӮжһңж·ұе…ҘеҲҶжһҗзҡ„иҜқпјҢPrefix LM е…¶е®һжҳҜ Encoder-Decoder жЁЎеһӢзҡ„еҸҳдҪ“пјҡж ҮеҮҶзҡ„ Encoder-Decoder жЁЎеһӢпјҢEncoder е’Ң Decoder еҗ„иҮӘдҪҝз”ЁдёҖдёӘзӢ¬з«Ӣзҡ„ TransformerпјӣиҖҢ Prefix LMпјҢзӣёеҪ“дәҺ Encoder е’Ң Decoder йҖҡиҝҮеҲҶеүІзҡ„ж–№ејҸпјҢеҲҶдә«дәҶеҗҢдёҖдёӘ Transformer з»“жһ„пјҢEncoder йғЁеҲҶеҚ з”Ёе·ҰйғЁпјҢDecoder йғЁеҲҶеҚ з”ЁеҸійғЁпјҢиҝҷз§ҚеҲҶеүІеҚ з”ЁжҳҜйҖҡиҝҮеңЁ Transformer еҶ…йғЁдҪҝз”Ё Attention Mask жқҘе®һзҺ°зҡ„гҖӮдёҺж ҮеҮҶ Encoder-Decoder зұ»дјјпјҢPrefix LM еңЁ Encoder йғЁеҲҶйҮҮз”Ё AE жЁЎејҸпјҢе°ұжҳҜд»»ж„ҸдёӨдёӘеҚ•иҜҚйғҪзӣёдә’еҸҜи§ҒпјҢDecoder йғЁеҲҶйҮҮз”Ё AR жЁЎејҸпјҢеҚіеҫ…з”ҹжҲҗзҡ„еҚ•иҜҚеҸҜд»Ҙи§ҒеҲ° Encoder дҫ§жүҖжңүеҚ•иҜҚе’Ң Decoder дҫ§е·Із»Ҹз”ҹжҲҗзҡ„еҚ•иҜҚпјҢдҪҶжҳҜдёҚиғҪзңӢжңӘжқҘе°ҡжңӘдә§з”ҹзҡ„еҚ•иҜҚпјҢе°ұжҳҜиҜҙжҳҜд»Һе·ҰеҲ°еҸіз”ҹжҲҗгҖӮзӣ®еүҚзҡ„дёҖдәӣеҜ№жҜ”е®һйӘҢиҜҒжҳҺпјҢеңЁе…¶е®ғжқЎд»¶зӣёеҗҢзҡ„жғ…еҶөдёӢпјҢе…ідәҺиҜӯиЁҖзҗҶи§Јзұ»зҡ„д»»еҠЎпјҲеҸӮиҖғ Encoder-AE йғЁеҲҶ Google T5 и®әж–Үдёӯзҡ„зӣёе…іе®һйӘҢпјүпјҢPrefix LM з»“жһ„зҡ„ж•ҲжһңиҰҒејұдәҺж ҮеҮҶ Encoder-Decoder з»“жһ„гҖӮиҝҷйҮҢжҳҜеҖјеҫ—ж·ұе…ҘжҖқиҖғдёӢзҡ„пјҢеӣ дёәзңӢдёҠеҺ» Prefix LM е’Ңж ҮеҮҶзҡ„ Encoder-Decoder з»“жһ„жҳҜзӯүд»·зҡ„гҖӮйӮЈд№ҲпјҢдёәд»Җд№Ҳе®ғзҡ„ж•ҲжһңжҜ”дёҚиҝҮ Encoder-Decoder з»“жһ„е‘ўпјҹжҲ‘жғіпјҢдёҖж–№йқўзҡ„еҺҹеӣ дј°и®ЎжҳҜдёӨиҖ…зҡ„еҸӮ数规模差ејӮеҜјиҮҙзҡ„пјӣеҸҰеӨ–дёҖж–№йқўпјҢеҸҜиғҪдёҺе®ғиҝҷз§ҚжЁЎејҸзҡ„ Decoder дҫ§еҜ№ Encoder дҫ§зҡ„ Attention жңәеҲ¶жңүе…ігҖӮеңЁ Decoder дҫ§пјҢTransformer зҡ„жҜҸеұӮ Block еҜ№ Encoder еҒҡ Attention зҡ„ж—¶еҖҷпјҢж ҮеҮҶзҡ„ Encoder-Decoder жЁЎејҸпјҢAttention жҳҜе»әз«ӢеңЁ Encoder дҫ§зҡ„жңҖеҗҺиҫ“еҮәдёҠпјҢиҝҷж ·еҸҜд»ҘиҺ·еҫ—жӣҙе…Ёйқўе®Ңж•ҙзҡ„е…ЁеұҖж•ҙеҗҲдҝЎжҒҜпјӣиҖҢ Prefix LM иҝҷз§Қз»“жһ„пјҢDecoder дҫ§зҡ„жҜҸеұӮ Transformer еҜ№ Encoder дҫ§зҡ„ AttentionпјҢжҳҜе»әз«ӢеңЁ Encoder зҡ„еҜ№еә”еұӮдёҠзҡ„пјҢеӣ дёәиҝҷз§ҚжЁЎејҸзҡ„ Encoder е’Ң Decoder еҲҶеүІдәҶеҗҢдёҖдёӘ Transformer з»“жһ„пјҢAttention еҸӘиғҪеңЁеҜ№еә”еұӮеҶ…зҡ„еҚ•иҜҚд№Ӣй—ҙиҝӣиЎҢпјҢеҫҲйҡҫдҪҺеұӮи·Ёй«ҳеұӮгҖӮиҝҷеҸҜиғҪжҳҜеҪұе“Қиҝҷз§Қз»“жһ„ж•Ҳжһңзҡ„еҺҹеӣ д№ӢдёҖгҖӮеҪ“然иҝҷеҸӘжҳҜдёӘдәәзҢңжөӢпјҢж— иҜҒжҚ®иҜҒжҳҺпјҢиҝҳиҜ·и°Ёж…ҺеҸӮиҖғгҖӮ
е…ідәҺиҜӯиЁҖз”ҹжҲҗзұ»зҡ„д»»еҠЎпјҢPrefix LM ж•ҲжһңиҷҪ然иҰҒејұдәҺ Encoder-Decoder з»“жһ„пјҲеҸӮиҖғ Encoder-Decoder е°ҸиҠӮ UniLM v2 и®әж–Үж•ҲжһңеҜ№жҜ”еӣҫпјүпјҢдҪҶжҳҜжҖ»дҪ“иҖҢиЁҖпјҢдёӨиҖ…зӣёе·®дёҚеӨ§пјҢзӣёеҜ№е…¶е®ғжЁЎеһӢпјҢPrefix LM з»“жһ„еңЁз”ҹжҲҗзұ»д»»еҠЎиЎЁзҺ°д№ҹжҜ”иҫғзӘҒеҮәгҖӮ
Prefix LM еӣ дёәжҳҜ Encoder-Decoder зҡ„еҸҳдҪ“пјҢжүҖд»ҘеҸҜд»ҘзңӢеҮәпјҢе®ғзҡ„дјҳеҠҝд№ҹеңЁдәҺеҸҜд»ҘеҗҢж—¶иҝӣиЎҢиҜӯиЁҖзҗҶи§Је’ҢиҜӯиЁҖз”ҹжҲҗзұ»д»»еҠЎпјҢиҖҢдё”зӣёеҜ№ Encoder-Decoder жқҘиҜҙпјҢеӣ дёәеҸӘз”ЁдәҶдёҖдёӘ TransformerпјҢжүҖд»ҘжЁЎеһӢжҜ”иҫғиҪ»пјҢиҝҷжҳҜ Prefix LM зҡ„дјҳеҠҝгҖӮзјәзӮ№еҲҷжҳҜеңЁж•Ҳжһңж–№йқўпјҢиІҢдјјиҰҒејұдәҺ Encoder-Decoder жЁЎеһӢзҡ„ж•ҲжһңпјҢиҜӯиЁҖзҗҶи§Јзұ»д»»еҠЎзӣёеҜ№жңүжҳҺжҳҫе·®и·қпјҢз”ҹжҲҗзұ»д»»еҠЎзҡ„ж•Ҳжһңзӣёе·®дёҚеӨ§гҖӮ
Permuted Language Model(PLM)
PLM жңҖж—©жҳҜеңЁ XLNet зҡ„и®әж–ҮдёӯжҸҗеҮәзҡ„пјҢзӣ®еүҚжңүдәӣеҗҺз»ӯжЁЎеһӢд№ҹеңЁ PLM дёҠиҝӣиЎҢж”№иҝӣпјҢжүҖд»ҘжҲ‘们жҠҠ PLM д№ҹж”ҫеңЁиҝҷйҮҢдёҖиө·иҜҙдёҖдёӢгҖӮеҜ№дәҺдёҚзҶҹжӮү XLNet зҡ„еҗҢеӯҰпјҢеҸҜд»ҘеҸӮиҖғеҺ»е№ҙ XLNet еҲҡеҮәжқҘж—¶еҖҷжҲ‘еҶҷзҡ„и§ЈиҜ»ж–Үз« пјҢиЎҘе……дёӢеҹәзЎҖзҹҘиҜҶпјҡ
жҺЁиҚҗйҳ…иҜ»















- йҳҹеҸӢ|жІҲжўҰиҫ°жӣқе…үйҳҹеҸӢвҖңдё‘з…§вҖқпјҢдҪҶжҳҫзӨәеҮәиүҜеҘҪзҡ„дәәж°”
- е…¬жј”|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢ第дә”ж¬Ўе…¬жј”зҺ°еңәпјҢжқҺж–Ҝдё№еҰ®з»„гҖҠжғ…дәәгҖӢеӨӘжғҠиүі
- зјәдҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- ж—¶е°ҡзӢӮжғіжӣІ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еҲ¶еӣўз»јпјҢеј йӣЁз»®з«ҷпјЈдҪҚпјҢз®ҖзәҰиЎ¬иЎЈзҪ•и§Ғз§ҖзҹҘжҖ§
- еҪ’дҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- 10жңҲ|еҚ°еәҰеҸ‘з”ҹ5.1зә§ең°йңҮпјҢйңҮжәҗж·ұеәҰ40еҚғзұі
- йҷҲиө«|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢжҲҗеӣўеӨңиҜ·дәҶ17дҪҚз”·еҳүе®ҫпјҢйҷҲиө«жғ№жқҘдёҖзүҮдәүи®®
- иҠӮзӣ®з»„|еӯҹдҪіпјҢеҲ«жҢЈжүҺдәҶпјҢгҖҠд№ҳйЈҺз ҙжөӘгҖӢиҠӮзӣ®з»„жҳҺж‘ҶзқҖжғіжҠҠдҪ ж·ҳжұ°
- е®Ғйқҷ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еӣўз»јпјҢе®ҒйқҷдёҮиҢңз ҙдёҚе’Ңдј й—»пјҢи·Ҝжј”и§Ҷйў‘ж¬ўд№җеӨҡ
- ж¶ҲжҒҜиө„и®Ҝ|д№ҳйЈҺз ҙжөӘ | еҸҳйқ©иҪ¬еһӢпјҡдәәжүҚеҹ№е…»вҖ”вҖ”дјҒдёҡиҪ¬еһӢдёҺеҲӣж–°зҡ„ж ёеҝғй©ұеҠЁеҠӣ