PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•( е…« )
еӨҡжЁЎжҖҒйў„и®ӯз»ғ
йҡҸзқҖеӯҳеӮЁе®№йҮҸи¶ҠжқҘи¶ҠеӨ§гҖҒзҪ‘з»ңдј иҫ“йҖҹеәҰи¶ҠжқҘи¶Ҡеҝ«гҖҒи®Ўз®—йҖҹеәҰи¶ҠжқҘи¶ҠејәпјҢйҷӨдәҶдј з»ҹзҡ„ж–Үеӯ—еҶ…е®№еӨ–пјҢеӣҫзүҮгҖҒи§Ҷйў‘гҖҒйҹійў‘зӯүеҗ„з§ҚеӨҡжЁЎжҖҒдҝЎжҒҜеңЁдә’иҒ”зҪ‘зҡ„еҶ…е®№еҚ жҜ”дёӯи¶ҠжқҘи¶ҠеӨҡгҖӮеҰӮдҪ•иһҚеҗҲеӨҡз§ҚжЁЎжҖҒдҝЎжҒҜиҝӣиЎҢеҶ…е®№зҗҶи§ЈпјҢе°ұеҸҳеҫ—и¶ҠжқҘи¶ҠйҮҚиҰҒгҖӮйӮЈд№ҲпјҢиғҪеҗҰе°ҶеӨҡжЁЎжҖҒдҝЎжҒҜзәіе…Ҙйў„и®ӯз»ғзҡ„жЎҶжһ¶д№ӢеҶ…е‘ўпјҹиҝҷжҳҜдёӘйқһеёёжңүзҺ°е®һд»·еҖјзҡ„й—®йўҳгҖӮ
еүҚж–Үжңүиҝ°пјҢиҮӘз”ұж–Үжң¬зҡ„йў„и®ӯз»ғпјҢжң¬иҙЁдёҠжҳҜи®©жЁЎеһӢд»Һжө·йҮҸиҮӘз”ұж–Үжң¬дёӯпјҢйҖҡиҝҮиҜӯиЁҖжЁЎеһӢзӯүд»»еҠЎпјҢжқҘеӯҰд№ е…¶дёӯи•ҙеҗ«зҡ„зҡ„иҜӯиЁҖеӯҰзҹҘиҜҶгҖӮз”ұжӯӨиҮӘ然引еҸ‘зҡ„й—®йўҳе°ұжҳҜпјҡеӨҡжЁЎжҖҒйў„и®ӯз»ғд№ҹжҳҜиҰҒе°Ҷжҹҗз§Қж–°еһӢзҡ„зҹҘиҜҶеЎһеҲ°жЁЎеһӢеҸӮж•°йҮҢпјҢйӮЈд№ҲпјҢиҝҷжҳҜдёҖз§Қд»Җд№Ҳж ·зҡ„зҹҘиҜҶе‘ўпјҹжң¬иҙЁдёҠпјҢеӨҡжЁЎжҖҒйў„и®ӯз»ғиҰҒеӯҰд№ зҡ„зҹҘиҜҶжҳҜдёӨз§ҚжЁЎжҖҒд№Ӣй—ҙпјҢжҲ–иҖ…еӨҡз§ҚжЁЎжҖҒд№Ӣй—ҙпјҢзҡ„зҹҘиҜҶеҚ•е…ғжҳ е°„е…ізі»гҖӮжҜ”еҰӮеҜ№дәҺж–Үеӯ— - еӣҫзүҮиҝҷдёӨз§ҚеӨҡжЁЎжҖҒдҝЎжҒҜжқҘиҜҙпјҢжҲ‘们еҸҜд»ҘжҠҠеӣҫзүҮжғіеғҸжҲҗдёҖз§Қзү№ж®Ҡзұ»еһӢзҡ„иҜӯиЁҖпјҢеӨҡжЁЎжҖҒйў„и®ӯз»ғеёҢжңӣи®©жЁЎеһӢеӯҰдјҡиҝҷдёӨз§ҚдёҚеҗҢжЁЎжҖҒд№Ӣй—ҙзҡ„иҜӯд№үжҳ е°„е…ізі»пјҢжҜ”еҰӮиғҪеӨҹе°ҶеҚ•иҜҚ "иӢ№жһң" е’ҢеӣҫзүҮдёӯеҮәзҺ°зҡ„иӢ№жһңеҢәеҹҹе»әз«Ӣиө·иҒ”зі»гҖӮжҲ–иҖ…иҜҙпјҢеёҢжңӣйҖҡиҝҮе°ҶдёҚеҗҢжЁЎжҖҒзҡ„дҝЎжҒҜжҳ е°„еҲ°зӣёеҗҢзҡ„иҜӯд№үз©әй—ҙпјҢжқҘеӯҰдјҡдёӨиҖ…д№Ӣй—ҙзҡ„иҜӯд№үжҳ е°„е…ізі»гҖӮ
ж–Үз« еӣҫзүҮ
еҰӮжһңжҲ‘们иғҪеӨҹжҲҗеҠҹең°еӯҰдјҡиҝҷз§ҚдёҚеҗҢеӘ’д»Ӣй—ҙзҡ„иҜӯд№үжҳ е°„пјҢйӮЈд№Ҳе°ұеҸҜд»ҘеҒҡеҫҲеӨҡжңүж„ҸжҖқзҡ„дәӢжғ…пјҢжҜ”еҰӮиҜҙеҸҘиҜқпјҢжҗңеҮәдёҺиҝҷеҸҘиҜқиҜӯд№үзӣёиҝ‘зҡ„еӣҫзүҮпјҲеҸӮиҖғдёҠеӣҫпјүпјӣжҲ–иҖ…еҸҚиҝҮжқҘпјҢиҫ“е…ҘдёҖдёӘеӣҫзүҮпјҢиғҪеӨҹжүҫеҲ°жҲ–иҖ…з”ҹжҲҗеҜ№еә”зҡ„ж–Үеӯ—жҸҸиҝ°гҖӮеҶҚжҜ”еҰӮ VQAпјҲеҸӮиҖғдёҠеӣҫпјүпјҢе°ұжҳҜз»ҷе®ҡдёҖеј еӣҫзүҮпјҢдҪ еҸҜд»Ҙй’ҲеҜ№еӣҫзүҮжҸҗеҮәдёҖдәӣй—®йўҳпјҢAI зі»з»ҹиғҪеӨҹеӣһзӯ”дҪ зҡ„й—®йўҳпјҢз»ҷеҮәжӯЈзЎ®зӯ”жЎҲгҖӮиҝҷж¶үеҸҠеҲ°еӣҫзүҮ - ж–Үеӯ—зҡ„и·ЁеӘ’дҪ“й—®зӯ”д»ҘеҸҠдёҖдәӣи·ЁеӘ’дҪ“зҡ„зҹҘиҜҶжҺЁзҗҶгҖӮиҖҢиҰҒжғіе®һзҺ°иҝҷз§ҚиғҪеҠӣпјҢеҰӮдҪ•йҖҡиҝҮйў„и®ӯз»ғжЁЎеһӢпјҢи®©жЁЎеһӢеӯҰдјҡдёӨз§ҚжЁЎжҖҒд№Ӣй—ҙзҡ„иҜӯд№үжҳ е°„е…ізі»е°ұжҳҜиҮіе…ійҮҚиҰҒзҡ„гҖӮжҲ‘们йқўдёҙзҡ„第дёҖдёӘй—®йўҳжҳҜпјҡд»Һд»Җд№Ҳж ·зҡ„ж•°жҚ®йҮҢжқҘеӯҰд№ дёҚеҗҢжЁЎжҖҒд№Ӣй—ҙзҡ„иҜӯд№үжҳ е°„е…ізі»е‘ўпјҹиҮӘз”ұж–Үжң¬зҡ„йў„и®ӯз»ғжЁЎеһӢпјҢеҸҜд»ҘйҮҮзәіжө·йҮҸж— ж ҮжіЁж•°жҚ®жқҘеҒҡпјҢ然иҖҢпјҢеӨҡжЁЎжҖҒйў„и®ӯз»ғиҰҒеӯҰд№ дёҚеҗҢжЁЎжҖҒдҝЎжҒҜй—ҙзҡ„иҜӯд№үжҳ е°„е…ізі»пјҢжүҖд»ҘйңҖиҰҒжңүж ҮжіЁеҘҪзҡ„ "жЁЎжҖҒ 1 - жЁЎжҖҒ 2" зҡ„еҜ№йҪҗж•°жҚ®пјҢжҜ”еҰӮпјҡж ҮжіЁеҘҪзҡ„ "ж–Үжң¬ - еӣҫзүҮ" жҲ–иҖ… "ж–Үжң¬ - и§Ҷйў‘" е№іиЎҢж•°жҚ®гҖӮеҸӘжңүе…·еӨҮи·ЁжЁЎжҖҒеҜ№йҪҗж•°жҚ®пјҢжЁЎеһӢжүҚжңүеҸҜиғҪд»ҺдёӯеӯҰд№ дёҚеҗҢеӘ’д»Ӣзұ»еһӢд№Ӣй—ҙзҡ„иҜӯд№үжҳ е°„е…ізі»гҖӮд»ҺиҝҷдёӘи§’еәҰи®ІпјҢзӣёеҜ№иҮӘз”ұж–Үжң¬йў„и®ӯз»ғжқҘиҜҙпјҢеӨҡжЁЎжҖҒйў„и®ӯз»ғеӣ дёәйңҖиҰҒжЁЎжҖҒеҜ№йҪҗи®ӯз»ғж•°жҚ®пјҢиҖҢиҝҷз§Қж•°жҚ®еҫҖеҫҖжҳҜйңҖиҰҒдәәе·Ҙж ҮжіЁзҡ„пјҢжүҖд»ҘеҸҜиҺ·еҫ—зҡ„ж•°жҚ®йҡҫеәҰеҸҠжҲҗжң¬е°ұй«ҳдәҶеҫҲеӨҡпјҢжҳҺжҳҫдёҚеҰӮж–Үжң¬йў„и®ӯз»ғйӮЈд№ҲиҮӘз”ұгҖӮ
жҖ»дҪ“иҖҢиЁҖпјҢзӣ®еүҚзҡ„еӨҡжЁЎжҖҒйў„и®ӯз»ғд»»еҠЎдёӯпјҢйҖҡеёёйғҪжҳҜ "еҸҢжЁЎжҖҒ" йў„и®ӯз»ғпјҢеёёи§Ғзҡ„еҢ…жӢ¬ "ж–Үжң¬ - еӣҫзүҮ"гҖҒ"ж–Үжң¬ - и§Ҷйў‘"гҖҒ"и§Ҷйў‘ - йҹійў‘" зӯүжЁЎжҖҒзұ»еһӢз»„еҗҲгҖӮе…¶дёӯпјҢ зӣёеҜ№иҖҢиЁҖпјҢ"ж–Үжң¬ - еӣҫзүҮ"зұ»еһӢзҡ„д»»еҠЎжҠҖжңҜеҸ‘еұ•жҜ”иҫғеҝ«пјҢе…¶е®ғзұ»еһӢзҡ„еӨҡжЁЎжҖҒзұ»еһӢеҸ‘еұ•зӣёеҜ№зј“ж…ўпјҢжҲ‘зҢңжөӢиҝҷйҮҢзҡ„дё»иҰҒеҺҹеӣ еңЁдәҺеҸҜз”Ёж ҮжіЁж•°жҚ®зҡ„е·®ејӮгҖӮ"ж–Үжң¬ - еӣҫзүҮ"зӣ®еүҚжңүдёҖдәӣ规模иҫҫеҲ°еҮ еҚҒдёҮеҲ°дёҠзҷҫдёҮ规模зҡ„ж ҮжіЁж•°жҚ®йӣҶеҗҲпјҢе…ёеһӢзҡ„жҜ”еҰӮ MS-COCOгҖҒVisual Gnome зӯүпјҢиҖҢе…¶е®ғзұ»еһӢзҡ„жЁЎжҖҒз»„еҗҲж•°жҚ®иІҢдјјзјәд№ҸеӨ§и§„жЁЎж•°жҚ®йӣҶеҗҲпјҢиҝҷдёҘйҮҚеҪұе“ҚдәҶйўҶеҹҹжҠҖжңҜиҝӣеұ•гҖӮдёӢйқўжҲ‘们д»Һ "ж–Үжң¬ - еӣҫзүҮ" иҝҷз§ҚжЁЎжҖҒз»„еҗҲжқҘе®Ҹи§Ӯд»Ӣз»ҚдёӢеӨҡжЁЎжҖҒйў„и®ӯз»ғзҡ„常规еҒҡжі•пјҢе…¶е®ғжЁЎжҖҒз»„еҗҲзҡ„жҠҖжңҜж–№жЎҲе·®дёҚеӨӘеӨҡпјҢжүҖзјәзҡ„еҸҜиғҪдё»иҰҒжҳҜж ҮжіЁеҘҪзҡ„жЁЎжҖҒеҜ№йҪҗж•°жҚ®гҖӮ
жҲ‘们д»ҺжЁЎеһӢз»“жһ„е’Ңи®ӯз»ғзӣ®ж ҮиҝҷдёӨдёӘи§’еәҰжқҘйҳҗиҝ°гҖӮзӣ®еүҚзҡ„еӨ§еӨҡж•°жҠҖжңҜж–№жЎҲеӨ§еҗҢе°ҸејӮпјҢдё»иҰҒе·®ејӮеңЁдәҺйҮҮз”ЁдәҶдёҚеҗҢзҡ„жЁЎеһӢз»“жһ„еҸҠдёҺдёҚеҗҢи®ӯз»ғзӣ®ж Үзҡ„е·®ејӮз»„еҗҲгҖӮ
еҒҮи®ҫжҲ‘们жңү "ж–Үжң¬ - еӣҫзүҮ" дёӨз§ҚжЁЎжҖҒж•°жҚ®пјҢйңҖиҰҒиҒ”еҗҲеӯҰд№ дёүз§Қйў„и®ӯз»ғжЁЎеһӢпјҡж–Үжң¬жЁЎжҖҒиҮӘиә«зҡ„йў„и®ӯз»ғжЁЎеһӢпјҢеӣҫзүҮжЁЎжҖҒиҮӘиә«зҡ„йў„и®ӯз»ғжЁЎеһӢпјҢд»ҘеҸҠдёӨдёӘжЁЎжҖҒд№Ӣй—ҙзҡ„иҜӯд№үеҜ№йҪҗйў„и®ӯз»ғжЁЎеһӢгҖӮд»ҺжЁЎеһӢз»“жһ„жқҘиҜҙпјҢзӣ®еүҚдё»жөҒзҡ„з»“жһ„жңүдёӨз§ҚпјҡеҸҢжөҒдәӨдә’жЁЎеһӢд»ҘеҸҠеҚ•жөҒдәӨдә’жЁЎеһӢгҖӮ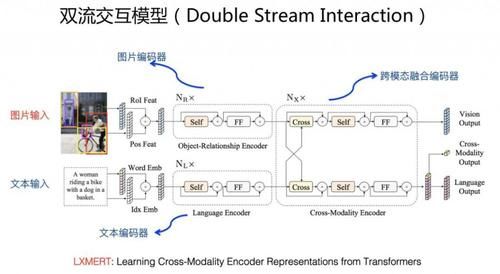
ж–Үз« еӣҫзүҮ
е…ёеһӢеҸҢжөҒдәӨдә’жЁЎеһӢз»“жһ„еҰӮдёҠеӣҫ LXMERT жЁЎеһӢжүҖзӨәгҖӮж–Үжң¬зј–з ҒеҷЁд»ЈиЎЁдёҖдёӘжөҒпјҢдёҖиҲ¬йҮҮз”Ё Transformer жЁЎеһӢжҚ•жҚүж–Үжң¬еҚ•иҜҚд№Ӣй—ҙзҡ„е…ізі»пјӣеӣҫзүҮзј–з ҒеҷЁд»ЈиЎЁеҸҰеӨ–дёҖдёӘжөҒпјҢдёҖиҲ¬д№ҹжҳҜйҮҮз”Ё Transformer жЁЎеһӢпјҢеҜ№дәҺеӣҫзүҮжқҘиҜҙпјҢдёҖиҲ¬з”Ё Faster-RCNN жЁЎеһӢиҜҶеҲ«еҮәеӣҫзүҮдёӯеҢ…еҗ«зҡ„еӨҡдёӘзү©дҪ“еҸҠе…¶еҜ№еә”зҡ„зҹ©еҪўдҪҚзҪ®дҝЎжҒҜпјҢе°Ҷй«ҳзҪ®дҝЎеәҰзҡ„зү©дҪ“еҸҠе…¶еҜ№еә”зҡ„дҪҚзҪ®дҝЎжҒҜдҪңдёәеӣҫзүҮдҫ§ Transformer зҡ„иҫ“е…ҘпјҢз”ЁжқҘеӯҰд№ еӣҫзүҮдёӯзү©е“Ғзҡ„зӣёдә’е…ізі»пјӣеңЁдёӨдёӘжөҒд№ӢдёҠпјҢеҶҚеҠ е…ҘйўқеӨ–зҡ„ Transformer жЁЎеһӢпјҢз”ЁдәҺиһҚеҗҲдёӨдёӘжЁЎжҖҒзҡ„иҜӯд№үжҳ е°„е…ізі»гҖӮеңЁиҝҷз§ҚеҸҢжөҒз»“жһ„дёҠпјҢжЁЎеһӢеҗҢж—¶еӯҰд№ ж–Үжң¬йў„и®ӯз»ғзӣ®ж ҮгҖҒеӣҫзүҮйў„и®ӯз»ғзӣ®ж ҮпјҢд»ҘеҸҠеӣҫзүҮ - ж–Үжң¬еҜ№йҪҗйў„и®ӯз»ғзӣ®ж ҮгҖӮдёҖиҲ¬ж–Үжң¬йў„и®ӯз»ғзӣ®ж Үе’Ңж ҮеҮҶзҡ„ Bert еҒҡжі•зұ»дјјпјҢйҖҡиҝҮйҡҸжңә Mask дёҖйғЁеҲҶж–Үжң¬еҚ•иҜҚзҡ„иҜӯиЁҖжЁЎеһӢжқҘеҒҡпјӣеӣҫзүҮйў„и®ӯз»ғзӣ®ж Үзұ»дјјпјҢеҸҜд»Ҙ Mask жҺүеӣҫзүҮдёӯеҢ…еҗ«зҡ„йғЁеҲҶзү©е“ҒпјҢиҰҒжұӮжЁЎеһӢжӯЈзЎ®йў„жөӢзү©е“Ғзұ»еҲ«жҲ–иҖ…йў„жөӢзү©е“Ғ Embedding зј–з ҒпјӣдёәдәҶиғҪеӨҹи®©дёӨдёӘжЁЎжҖҒиҜӯд№үеҜ№йҪҗпјҢдёҖиҲ¬иҝҳиҰҒеӯҰд№ дёҖдёӘи·ЁжЁЎжҖҒзӣ®ж ҮпјҢ常规еҒҡжі•жҳҜе°ҶеҜ№йҪҗиҜӯж–ҷдёӯзҡ„ "ж–Үжң¬ - еӣҫзүҮ" дҪңдёәжӯЈдҫӢпјҢйҡҸжңәйҖүжӢ©йғЁеҲҶеӣҫзүҮжҲ–иҖ…ж–Үжң¬дҪңдёәиҙҹдҫӢпјҢжқҘиҰҒжұӮжЁЎеһӢжӯЈзЎ®еҒҡдәҢеҲҶзұ»й—®йўҳпјҢйҖҡиҝҮиҝҷз§Қж–№ејҸйҖјиҝ«жЁЎеһӢеӯҰд№ дёӨз§ҚжЁЎжҖҒй—ҙзҡ„еҜ№йҪҗе…ізі»гҖӮ е…ёеһӢзҡ„еҸҢжөҒжЁЎеһӢеҢ…жӢ¬ LXMERTгҖҒViLBERT зӯүгҖӮ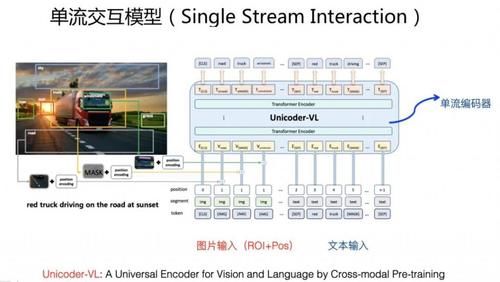
ж–Үз« еӣҫзүҮ
е…ёеһӢзҡ„еҚ•жөҒдәӨдә’жЁЎеһӢз»“жһ„еҰӮдёҠеӣҫ Unicoder-VL жЁЎеһӢжүҖзӨәгҖӮеҚ•жөҒе’ҢеҸҢжөҒзҡ„еҢәеҲ«еңЁдәҺпјҡеҚ•жөҒжЁЎеһӢеҸӘз”ЁдёҖдёӘ TransformerпјҢиҖҢеҸҢжөҒжЁЎеһӢпјҢеҰӮдёҠжүҖиҝ°пјҢйңҖиҰҒдёүдёӘ Transformer еҗ„иҮӘеҲҶе·ҘеҚҸдҪңгҖӮиҫ“е…Ҙзҡ„еӣҫзүҮпјҢз»ҸиҝҮдёҠиҝ°зҡ„ Faster-RCNN зү©дҪ“иҜҶеҲ«е’ҢдҪҚзҪ®зј–з ҒеҗҺпјҢе’Ңж–Үжң¬еҚ•иҜҚжӢјжҺҘпјҢж•ҙдҪ“дҪңдёә Transformer жЁЎеһӢзҡ„иҫ“е…ҘгҖӮд№ҹе°ұжҳҜиҜҙпјҢеҚ•жөҒжЁЎеһӢйқ еҚ•дёӘ TransformerпјҢеҗҢж—¶еӯҰд№ ж–Үжң¬еҶ…йғЁеҚ•иҜҚдәӨдә’гҖҒеӣҫзүҮдёӯеҢ…еҗ«зү©дҪ“д№Ӣй—ҙеӨ§зҡ„дәӨдә’пјҢд»ҘеҸҠж–Үжң¬ - еӣҫзүҮд№Ӣй—ҙзҡ„з»ҶзІ’еәҰиҜӯд№үеҚ•е…ғд№Ӣй—ҙзҡ„дәӨдә’дҝЎжҒҜгҖӮеҚ•жөҒжЁЎеһӢзҡ„йў„и®ӯз»ғзӣ®ж ҮпјҢдёҺеҸҢжөҒдәӨдә’жЁЎеһӢжҳҜзұ»дјјзҡ„пјҢеҫҖеҫҖд№ҹйңҖиҰҒиҒ”еҗҲеӯҰд№ ж–Үжң¬йў„и®ӯз»ғгҖҒеӣҫзүҮйў„и®ӯз»ғд»ҘеҸҠеҜ№йҪҗйў„и®ӯз»ғдёүдёӘзӣ®ж ҮгҖӮ е…ёеһӢзҡ„еҚ•жөҒжЁЎеһӢеҢ…жӢ¬ Unicoder-VLгҖҒVisualBERTгҖҒVL-VERTгҖҒUNITER зӯүгҖӮ
жҺЁиҚҗйҳ…иҜ»
















- йҳҹеҸӢ|жІҲжўҰиҫ°жӣқе…үйҳҹеҸӢвҖңдё‘з…§вҖқпјҢдҪҶжҳҫзӨәеҮәиүҜеҘҪзҡ„дәәж°”
- е…¬жј”|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢ第дә”ж¬Ўе…¬жј”зҺ°еңәпјҢжқҺж–Ҝдё№еҰ®з»„гҖҠжғ…дәәгҖӢеӨӘжғҠиүі
- зјәдҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- ж—¶е°ҡзӢӮжғіжӣІ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еҲ¶еӣўз»јпјҢеј йӣЁз»®з«ҷпјЈдҪҚпјҢз®ҖзәҰиЎ¬иЎЈзҪ•и§Ғз§ҖзҹҘжҖ§
- еҪ’дҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- 10жңҲ|еҚ°еәҰеҸ‘з”ҹ5.1зә§ең°йңҮпјҢйңҮжәҗж·ұеәҰ40еҚғзұі
- йҷҲиө«|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢжҲҗеӣўеӨңиҜ·дәҶ17дҪҚз”·еҳүе®ҫпјҢйҷҲиө«жғ№жқҘдёҖзүҮдәүи®®
- иҠӮзӣ®з»„|еӯҹдҪіпјҢеҲ«жҢЈжүҺдәҶпјҢгҖҠд№ҳйЈҺз ҙжөӘгҖӢиҠӮзӣ®з»„жҳҺж‘ҶзқҖжғіжҠҠдҪ ж·ҳжұ°
- е®Ғйқҷ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еӣўз»јпјҢе®ҒйқҷдёҮиҢңз ҙдёҚе’Ңдј й—»пјҢи·Ҝжј”и§Ҷйў‘ж¬ўд№җеӨҡ
- ж¶ҲжҒҜиө„и®Ҝ|д№ҳйЈҺз ҙжөӘ | еҸҳйқ©иҪ¬еһӢпјҡдәәжүҚеҹ№е…»вҖ”вҖ”дјҒдёҡиҪ¬еһӢдёҺеҲӣж–°зҡ„ж ёеҝғй©ұеҠЁеҠӣ