PTM|д№ҳйЈҺз ҙжөӘзҡ„ PTMпјҢж·ұеәҰи§ЈиҜ»йў„и®ӯз»ғжЁЎеһӢзҡ„иҝӣеұ•( дёғ )
з”ұжӯӨиҝӣдёҖжӯҘжҺЁзҗҶпјҢжҲ‘们еҸҜд»Ҙеҫ—еҮәеҰӮдёӢз»“и®әпјҡзӣ®еүҚйў„и®ӯз»ғжЁЎеһӢйғҪйҮҮз”Ёзҡ„ Transformer з»“жһ„пјҢд»ҺжЁЎеһӢе®№йҮҸжҲ–жЁЎеһӢеӨҚжқӮеәҰжқҘиҜҙжҳҜи¶іеӨҹеӨҚжқӮзҡ„гҖӮе°ұжҳҜиҜҙпјҢTransformer з»“жһ„жң¬иә«пјҢзӣ®еүҚ并йқһеҲ¶зәҰйў„и®ӯз»ғжЁЎеһӢж•Ҳжһңзҡ„瓶йўҲпјҢжҲ‘们еҸҜд»Ҙд»…д»…йҖҡиҝҮеўһеҠ й«ҳиҙЁйҮҸж•°жҚ®гҖҒеўһеҠ жЁЎеһӢеӨҚжқӮеәҰй…Қд»Ҙжӣҙе……еҲҶең°жЁЎеһӢи®ӯз»ғпјҢе°ұд»Қ然иғҪеӨҹжһҒеӨ§е№…еәҰең°жҸҗеҚҮ Bert зҡ„жҖ§иғҪгҖӮ
иҝҷиҜҙжҳҺдәҶд»Җд№Ҳе‘ўпјҹиҝҷиҜҙжҳҺдәҶеӨ§ж•°жҚ® + еӨ§жЁЎеһӢзҡ„жҡҙеҠӣзҫҺеӯҰпјҢиҝҷжқЎзІ—жҡҙз®ҖжҙҒдҪҶжңүж•Ҳзҡ„и·ҜеӯҗпјҢиҝҳиҝңиҝңжІЎжңүиө°еҲ°е°ҪеӨҙпјҢиҝҳжңүеҫҲеӨ§зҡ„жҪңеҠӣеҸҜжҢ–гҖӮе°Ҫз®ЎиҝҷеёҰжқҘзҡ„еүҜдҪңз”ЁжҳҜпјҡеҘҪзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢи®ӯз»ғжҲҗжң¬дјҡйқһеёёй«ҳпјҢиҝҷдёҚжҳҜжҜҸдёӘз ”з©¶иҖ…йғҪиғҪеӨҹжүҝеҸ—зҡ„гҖӮдҪҶжҳҜпјҢжҲ‘зҡ„ж„Ҹи§ҒпјҢиҝҷе…¶е®һжҳҜдёӘеҘҪдәӢжғ…гҖӮеҰӮжһңд»…д»…йҖҡиҝҮеҠ ж•°жҚ®гҖҒжү©жЁЎеһӢе°ұиғҪиҺ·еҫ—жӣҙеҘҪзҡ„ж•ҲжһңпјҢиҝҷд№Ҳз®ҖеҚ•зҡ„ж–№ејҸе°ұиғҪжҺЁеҠЁжЁЎеһӢж•ҲжһңдёҚж–ӯдёҠеҚҮпјҢжҺЁеҠЁжӣҙеӨҡеә”з”ЁиҺ·еҫ—жӣҙеҘҪж•ҲжһңпјҢиҝҷдёҚжҳҜеӨ©еӨ§зҡ„еҘҪдәӢд№ҲпјҹиҮідәҺз”ұжӯӨеёҰжқҘзҡ„еӨ§жЁЎеһӢиҗҪең°йҡҫзҡ„й—®йўҳпјҢжҲ‘зӣёдҝЎеҸҜд»ҘйҖҡиҝҮжҗӯй…ҚзҹҘиҜҶи’ёйҰҸзӯүжҠҠжЁЎеһӢеҒҡе°Ҹзҡ„ж–№жЎҲжқҘиҺ·еҫ—и§ЈеҶігҖӮе°ұжҳҜиҜҙпјҢеҫҲеҸҜиғҪйў„и®ӯз»ғжЁЎеһӢеҸ‘еұ•дјҡиө°еҮәдёҖдёӘе“‘й“ғжЁЎејҸпјҡдёӨеӨҙеӨ§пјҢдёӯй—ҙе°ҸгҖӮдёӨдёӘеӨ§еӨҙдёӯпјҢдёҖеӨҙжҳҜи¶ҠжқҘи¶ҠеӨ§зҡ„йў„и®ӯз»ғжЁЎеһӢпјҢдёҖеӨҙжҳҜиҝҪжұӮеҗ„з§ҚжҠҖжңҜжқҘе®һз”ЁеҢ–ең°жҠҠжЁЎеһӢеҒҡе°ҸпјҢиҝҷдёӨз«Ҝдјҡи¶ҠжқҘи¶ҠйҮҚиҰҒгҖӮ
еҰӮжһңдёҠиҝ°еҒҮи®ҫжҲҗз«ӢпјҢеҚійў„и®ӯз»ғйўҶеҹҹзҡ„жҡҙеҠӣзҫҺеӯҰдҫқ然жҡҙеҠӣдё”зҫҺдёҪпјҢйӮЈд№Ҳд»Һд»ҠеҫҖеҗҺзҡ„жЁЎеһӢж”№иҝӣпјҢжҲ‘们еә”иҜҘжҖҺд№Ҳиө°е‘ўпјҹжҲ‘зҡ„ж„ҹи§үпјҢеә”иҜҘдјҳе…ҲжҺўзҙўеӨ§ж•°жҚ® + еӨ§жЁЎеһӢзҡ„и·ҜпјҢе…Ҳиө°еҲ°жҡҙеҠӣзҫҺеӯҰзҡ„е°ҪеӨҙпјҢ然еҗҺеҶҚйӣҶдёӯзІҫеҠӣжҺўзҙўжЁЎеһӢжң¬иә«зҡ„ж”№иҝӣгҖӮе°ұжҳҜиҜҙпјҢжҲ‘们еә”иҜҘе…ҲжҠҠж•°жҚ®зәўеҲ©еҗғе®ҢпјҢиҖҢдёҚжҳҜдјҳе…ҲеҸ‘еұ•ж–°еһӢжЁЎеһӢпјҢеҪ“然дёӨиҖ…еҸҜд»Ҙ并иЎҢеҒҡпјҢдҪҶжҳҜеҺҹеҲҷдёҠпјҢж–°еһӢжЁЎеһӢдјҳе…Ҳзә§дёҚеҰӮе…ҲжҠҠж•°жҚ®зәўеҲ©еҗғе®ҢгҖӮдёәд»Җд№Ҳиҝҷд№ҲиҜҙе‘ўпјҹеӣ дёәпјҢзӣ®еүҚеҫҲеӨҡз ”з©¶иЎЁжҳҺпјҡеӨ§еӨҡж•°ж”№иҝӣж–°жЁЎеһӢеёҰжқҘзҡ„жҸҗеҚҮпјҢж №жң¬жҜ”дёҚиҝҮжҸҗеҚҮж•°жҚ®иҙЁйҮҸж•°йҮҸзҡ„еҗҢж—¶жү©е……жЁЎеһӢе®№йҮҸеёҰжқҘзҡ„收зӣҠгҖӮиҖҢдёҖдәӣж–°жЁЎеһӢзҡ„жңүж•ҲжҖ§пјҢеңЁж•°жҚ®йҮҸе°Ҹзҡ„ж—¶еҖҷеҸҜиғҪжҳҜжңүж•Ҳзҡ„пјҢдҪҶеҫҲеҸҜиғҪеҸ‘з”ҹзҡ„дёҖ幕жҳҜпјҢеҪ“ж•°жҚ®еўһеӨ§жЁЎеһӢе®№йҮҸеҠ еӨ§еҗҺпјҢеҫҲеӨҡж”№иҝӣдёҚеҶҚжңүж•ҲгҖӮд№ҹе°ұжҳҜиҜҙпјҢзӣ®еүҚеҫҲеӨҡж–°жЁЎеһӢзҡ„дҪңз”ЁпјҢеҫҲеҸҜиғҪжҳҜеўһеҠ дәҶзү№ж®Ҡзұ»еһӢзҡ„иҜӯиЁҖзҹҘиҜҶзҡ„зј–з Ғе’ҢжіӣеҢ–иғҪеҠӣпјҢдҪҶжҳҜпјҢиҝҷжҳҜе®Ңе…ЁеҸҜд»ҘйҖҡиҝҮеўһеҠ ж•°жҚ®ж•°йҮҸе’ҢиҙЁйҮҸпјҢ并еҠ еӨ§жЁЎеһӢжқҘиҫҫжҲҗзҡ„пјҢиҝҷз§Қж–№ејҸеҸҲжҜ”иҫғз®ҖеҚ•зӣҙи§ӮгҖӮжүҖд»ҘпјҢиҝҷжҳҜдёәдҪ•жҲ‘и§үеҫ—еә”иҜҘе…ҲжҠҠзІҫеҠӣж”ҫеҲ°"еӨ§ж•°жҚ® + еӨ§жЁЎеһӢ" дёҠпјҢ然еҗҺеҶҚйӣҶдёӯзІҫеҠӣиҝӣиЎҢжЁЎеһӢж”№иҝӣзҡ„дё»иҰҒеҺҹеӣ гҖӮ
зҹҘиҜҶиЎҘд№ зҸӯпјҡе…¶е®ғзҹҘиҜҶзҡ„еј•е…Ҙ
жң¬ж–ҮејҖеӨҙи®ІиҝҮпјҢеӨ§еӨҡж•°йў„и®ӯз»ғжЁЎеһӢжҳҜд»ҺиҮӘз”ұж–Үжң¬дёӯеӯҰд№ иҜӯиЁҖзҹҘиҜҶгҖӮдҪҶжҳҜпјҢеҫҲжҳҺжҳҫпјҢжҲ‘们иғҪи®©жЁЎеһӢеӯҰзҡ„пјҢиӮҜе®ҡдёҚжӯўиҮӘз”ұж–Үжң¬иҝҷдёҖз§Қзұ»еһӢгҖӮзҗҶи®әдёҠпјҢд»»дҪ•еҢ…еҗ«зҹҘиҜҶзҡ„ж•°жҚ®пјҢйғҪжңүдәӣе…ҲйӘҢзҹҘиҜҶеҸҜдҫӣйў„и®ӯз»ғжЁЎеһӢеӯҰд№ гҖӮжҲ‘зҡ„ж„ҹи§үпјҢйў„и®ӯз»ғжЁЎеһӢзҡ„еҸ‘еұ•пјҢдјҡи¶ҠжқҘи¶ҠеғҸдәәи„‘пјҢж—ҘзӣҠеҸҳжҲҗдёҖдёӘй»‘зӣ’еӯҗгҖӮе°ұжҳҜиҜҙпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮдёҖе®ҡжүӢж®өпјҢе–Ӯз»ҷе®ғж•°жҚ®пјҢе®ғе°ұдјҡеӯҰдјҡе…¶дёӯеҢ…еҗ«зҡ„зҹҘиҜҶгҖӮдҪҶжҳҜпјҢе®ғжҳҜжҖҺд№ҲеӯҰдјҡзҡ„пјҢеӯҰеҲ°дәҶд»Җд№ҲпјҢиҝҷеҫҲеҸҜиғҪеҜ№жҲ‘们жқҘиҜҙпјҢдјҡи¶ҠжқҘи¶Ҡйҡҫд»ҘзҗҶи§ЈпјҢе°ұжҳҜиҜҙпјҢйҡҸзқҖйў„и®ӯз»ғжЁЎеһӢеӯҰд№ йўҶеҹҹзҡ„жӢ“еұ•пјҢиҝҷдёӘй»‘зӣ’еӯҗпјҢеҸҜиғҪдјҡи¶ҠжқҘи¶Ҡй»‘гҖӮдёӢйқўжҲ‘们д»Ӣз»ҚдёӨдёӘе…ёеһӢзҡ„е…¶е®ғйўҶеҹҹпјҢзңӢзңӢйў„и®ӯз»ғжЁЎеһӢжҳҜжҖҺд№ҲеӯҰзҡ„гҖӮеҪ“然пјҢжҲ‘зӣёдҝЎиҝҷз§Қйў„и®ӯз»ғж–№ејҸпјҢдјҡжӢ“еұ•еҲ°и¶ҠжқҘи¶ҠеӨҡзҡ„е…¶е®ғзұ»еһӢзҡ„ж•°жҚ®жҲ–йўҶеҹҹпјҢиҝҷд№ҹжҳҜйў„и®ӯз»ғжЁЎеһӢйўҶеҹҹпјҢдёҖдёӘжҜ”иҫғжҳҺжҷ°зҡ„еҸ‘еұ•и¶ӢеҠҝгҖӮ
жҳҫзӨәзҹҘиҜҶзҡ„еј•е…Ҙ
еҺҹе§Ӣ Bert зҡ„иҜӯиЁҖеӯҰзҹҘиҜҶпјҢжҳҜд»ҺеӨ§йҮҸиҮӘз”ұж–Үжң¬дёӯиҮӘдё»еӯҰд№ зҡ„пјҢйӮЈд№ҲеҫҲиҮӘ然зҡ„дёҖдёӘй—®йўҳе°ұжҳҜпјҡжҲ‘们иҝҮеҺ»е·Із»ҸйҖҡиҝҮдёҖдәӣжҠҖжңҜжүӢж®өпјҢеҪ’зәіеҮәеӨ§йҮҸзҡ„з»“жһ„еҢ–зҹҘиҜҶпјҢжҜ”еҰӮзҹҘиҜҶеӣҫи°ұпјӣжҲ–иҖ…е·Із»Ҹе»әз«ӢдәҶеҫҲеӨҡзҹҘиҜҶеҲҶжһҗе·Ҙе…·пјҢжҜ”еҰӮе‘ҪеҗҚе®һдҪ“иҜҶеҲ«зі»з»ҹзӯүгҖӮйӮЈд№ҲиғҪеҗҰеҲ©з”ЁиҝҷдәӣзҹҘиҜҶиҜҶеҲ«е·Ҙе…·пјҢжҠ‘жҲ–е·Іжңүзҡ„з»“жһ„еҢ–зҹҘиҜҶпјҢи®©йў„и®ӯз»ғжЁЎеһӢиғҪеӨҹзӣҙжҺҘеӯҰеҲ°иҝҷдәӣзҹҘиҜҶпјҹ
зӣ®еүҚд№ҹжңүеҫҲеӨҡе·ҘдҪңеңЁеҒҡиҝҷдёӘдәӢжғ…пјҢе°ұжҳҜи®©йў„и®ӯз»ғжЁЎеһӢиғҪеӨҹзј–з ҒжӣҙеӨҡзҡ„з»“жһ„еҢ–зҹҘиҜҶжҲ–иҖ…иҜӯиЁҖзҹҘиҜҶгҖӮиҮідәҺеҰӮдҪ•еҒҡпјҢжңүдёӨз§Қе…ёеһӢзҡ„жҖқи·ҜпјҡдёҖз§Қд»ҘзҷҫеәҰ ERNIE дёәд»ЈиЎЁпјӣдёҖз§Қд»Ҙжё…еҚҺ ERNIE дёәд»ЈиЎЁгҖӮиҝҷдёӨдёӘе·ҘдҪңжҳҜжңҖж—©еҒҡиҝҷдёӘдәӢжғ…зҡ„пјҢе·®дёҚеӨҡеҗҢж—¶еҮәжқҘпјҢдҪҶжҖқи·ҜдёҚеҗҢпјҢжӯЈеҘҪжҳҜдёӨз§Қе…·еӨҮд»ЈиЎЁжҖ§зҡ„ж–№жЎҲгҖӮ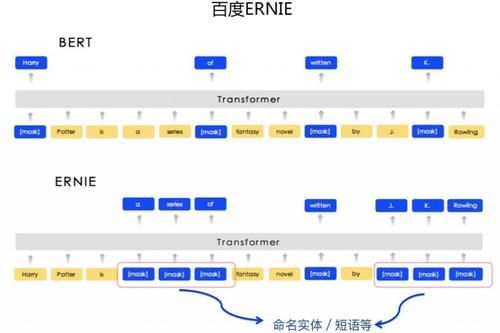
ж–Үз« еӣҫзүҮ
зҷҫеәҰ ERNIE зҡ„жҖқи·ҜжҳҜпјҡеңЁйў„и®ӯз»ғйҳ¶ж®өиў« Mask жҺүзҡ„еҜ№иұЎдёҠеҒҡж–Үз« пјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁжҜ”еҰӮе‘ҪеҗҚе®һдҪ“иҜҶеҲ«е·Ҙе…·пјҸзҹӯиҜӯиҜҶеҲ«е·Ҙе…·пјҢе°Ҷиҫ“е…Ҙдёӯзҡ„е‘ҪеҗҚе®һдҪ“жҲ–иҖ…йғЁеҲҶзҹӯиҜӯ Mask жҺүпјҲеҸӮиҖғдёҠеӣҫпјүпјҢиҝҷдәӣиў« Mask жҺүзҡ„зүҮж–ӯпјҢд»ЈиЎЁдәҶжҹҗз§Қзұ»еһӢзҡ„иҜӯиЁҖеӯҰзҹҘиҜҶпјҢйҖҡиҝҮиҝҷз§Қж–№ејҸпјҢејәиҝ«йў„и®ӯз»ғжЁЎеһӢеҺ»ејәеҢ–ең°еӯҰд№ зӣёе…ізҹҘиҜҶгҖӮ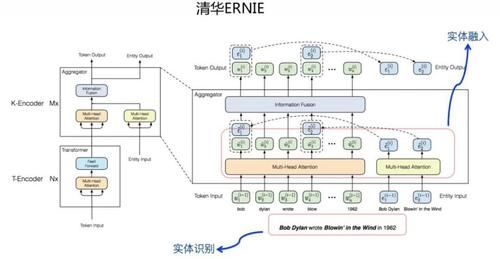
ж–Үз« еӣҫзүҮ
жё…еҚҺ ERNIE еҲҷжҳҜеҸҰеӨ–дёҖз§ҚжҖқи·ҜпјҡжҲ‘们已з»Ҹжңүдәӣз»“жһ„еҢ–зҹҘиҜҶжҲ–иҖ…е®һдҪ“е…ізі»зҹҘиҜҶзӯүзҺ°жҲҗзҡ„еӨ–йғЁзҹҘиҜҶеә“пјҢеҸҜд»ҘеңЁйў„и®ӯз»ғзҡ„иҝҮзЁӢдёӯпјҢйҖҡиҝҮе·Ҙе…·жүҫеҮәеҸҘдёӯзҡ„е‘ҪеҗҚе®һдҪ“пјҢеҸҘдёӯзҡ„е‘ҪеҗҚе®һдҪ“еҸҜд»Ҙи§ҰеҸ‘зҹҘиҜҶеә“дёӯе…¶е®ғзӣёе…іе®һдҪ“пјҢ然еҗҺйў„и®ӯз»ғжЁЎеһӢйҖҡиҝҮзү№ж®Ҡзҡ„з»“жһ„пјҢжқҘиһҚеҗҲж–Үжң¬е’Ңз»“жһ„еҢ–зҹҘиҜҶпјҢд»ҘиҝӣдёҖжӯҘдҝғиҝӣиҜӯиЁҖзҡ„зҗҶи§ЈпјҲеҸӮиҖғдёҠеӣҫпјүгҖӮиҝҷжҳҜеҸҰеӨ–дёҖз§ҚжҖқи·ҜгҖӮе…ідәҺзҹҘиҜҶзҡ„иһҚе…ҘпјҢеҗҺз»ӯиҝҳжңүеҫҲеӨҡе·ҘдҪңпјҢдҪҶжҳҜеӨ§дҪ“иө°зҡ„жҳҜдёҠйқўдёӨжқЎи·Ҝзәҝд№ӢдёҖгҖӮе…ідәҺе°ҶжҳҫзӨәзҹҘиҜҶжҲ–иҖ…з»“жһ„еҢ–зҹҘиҜҶеј•е…Ҙйў„и®ӯз»ғжЁЎеһӢпјҢжҲ‘жҳҜиҝҷд№ҲзңӢзҡ„пјҢзәҜеұһдёӘдәәж„Ҹи§Ғпјҡ
жҲ‘и§үеҫ—пјҢеҒҮи®ҫиҜҙжҲ‘们用жқҘйў„и®ӯз»ғзҡ„ж•°жҚ®йҮҸзү№еҲ«зү№еҲ«еӨ§пјҢиҖҢдё”зү№еҫҒжҠҪеҸ–еҷЁзҡ„иғҪеҠӣзү№еҲ«ејәгҖӮзҗҶи®әдёҠпјҢз»“жһ„еҢ–зҹҘиҜҶжҳҜи•ҙеҗ«еңЁиҝҷдәӣж–Үжң¬еҶ…зҡ„пјҢеӣ дёәжҲ‘们зҡ„еӨ–йғЁзҹҘиҜҶеә“д№ҹжҳҜйҖҡиҝҮжҠҖжңҜжүӢж®өд»ҺиҮӘз”ұж–Үжң¬йҮҢжҢ–жҺҳеҮәжқҘзҡ„гҖӮеҒҮи®ҫдёҠйқўдёӨдёӘжқЎд»¶еҗҢж—¶иғҪеӨҹиў«ж»Ўи¶іпјҢзҗҶи®әдёҠпјҢдёҚеӨӘйңҖиҰҒеҚ•зӢ¬еҶҚжҠҠз»“жһ„еҢ–зҹҘиҜҶзӢ¬з«ӢиЎҘе……з»ҷ Bert иҝҷзұ»йў„и®ӯз»ғжЁЎеһӢпјҢйў„и®ӯз»ғжЁЎеһӢеә”иҜҘиғҪеӨҹзӣҙжҺҘд»ҺиҮӘз”ұж–Үжң¬дёӯе°ұеӯҰдјҡиҝҷдәӣзҹҘиҜҶгҖӮдҪҶжҳҜпјҢд»ҘжҲ‘们зӣ®еүҚзҡ„жҠҖжңҜжқЎд»¶пјҢдёҠйқўдёӨдёӘжқЎд»¶е®Ңе…Ёиў«ж»Ўи¶іпјҢиҝҳжҳҜжңүдёҖе®ҡйҡҫеәҰзҡ„гҖӮдәҺжҳҜпјҢеңЁиҝҷз§ҚзәҰжқҹдёӢпјҢж„ҹи§үзӢ¬з«ӢејәеҢ–зҹҘиҜҶпјҢи®© Bert еңЁзј–з Ғзҡ„ж—¶еҖҷжӣҙйҮҚи§Ҷиҝҷдәӣз»“жһ„еҢ–зҹҘиҜҶпјҢзңӢдёҠеҺ»жҳҜжңүдёҖе®ҡиЎҘе……дҪңз”Ёзҡ„гҖӮжҲ‘зҢңжөӢпјҢжҜ”иҫғй«ҳйў‘еҮәзҺ°зҡ„зҹҘиҜҶпјҢе·Із»ҸиғҪеӨҹйҖҡиҝҮ常规зҡ„иҜӯиЁҖжЁЎеһӢйў„и®ӯз»ғиғҪеӨҹжҚ•иҺ·дәҶпјҢеҫҲеҸҜиғҪеҜ№дәҺйӮЈдәӣеҒҸеҶ·й—Ёзҡ„зҹҘиҜҶпјҢеј•е…Ҙз»“жһ„еҢ–зҹҘиҜҶпјҢдјҡеҜ№йў„и®ӯз»ғжЁЎеһӢеҒҡдёӢжёёд»»еҠЎжңүзӣҙжҺҘдҝғиҝӣдҪңз”ЁгҖӮиҖҢеҸҜд»Ҙйў„и§Ғзҡ„жҳҜпјҡйҡҸзқҖжңәеҷЁиө„жәҗиғҪеҠӣи¶ҠжқҘи¶ҠејәеӨ§пјҢеҰӮжһңеңЁз¬¬дёҖдёӘйў„и®ӯз»ғйҳ¶ж®өпјҢдёҚж–ӯеҠ еӨ§ж•°жҚ®ж•°йҮҸе’ҢиҙЁйҮҸпјҢдёҚж–ӯеўһеҠ Transformer жЁЎеһӢе®№йҮҸпјҢйӮЈд№ҲпјҢеҚ•зӢ¬иЎҘе……з»“жһ„еҢ–зҹҘиҜҶз»ҷйў„и®ӯз»ғжЁЎеһӢпјҢ收зӣҠеҸҜиғҪдјҡи¶ҠжқҘи¶Ҡе°ҸгҖӮеҪ“然пјҢд»Ҙзӣ®еүҚзҡ„жҠҖжңҜеҸ‘еұ•йҳ¶ж®өпјҢж„ҹи§үиҝҷдёӘдәӢжғ…иҝҳжңүз©әй—ҙе’ҢжҪңеҠӣеҸҜжҢ–жҺҳгҖӮеҪ“然пјҢдёҠйқўиҜҙзҡ„жҳҜйҖҡз”ЁзҹҘиҜҶпјҢеҰӮжһңжүӢдёҠзҡ„еӨ–йғЁзҹҘиҜҶеә“пјҢйўҶеҹҹжҖ§еҫҲејәпјҢйҖҡз”Ёи®ӯз»ғж•°жҚ®дёӯеҢ…еҗ«зҡ„зӣёе…ійўҶеҹҹж•°жҚ®еҫҲе°‘пјҢйӮЈд№ҲпјҢзӣҙжҺҘжҠҠзҹҘиҜҶеј•е…ҘпјҢеҜ№дәҺи§ЈеҶій—®йўҳиҝҳжҳҜеҫҲжңүеҝ…иҰҒзҡ„гҖӮ
жҺЁиҚҗйҳ…иҜ»





![[з»јиүәиҠӮзӣ®]ж—©еә”иҜҘиў«еҒңж’ӯзҡ„еҮ дёӘз»јиүәиҠӮзӣ®пјҢдёҚд»…еҶ…幕让дәәж°”ж„ӨпјҢз”ҡиҮіиҝҳиҜҜеҜјйқ’е°‘е№ҙ](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/4d71220ab187d1a1594708332a467e22.jpg)









- йҳҹеҸӢ|жІҲжўҰиҫ°жӣқе…үйҳҹеҸӢвҖңдё‘з…§вҖқпјҢдҪҶжҳҫзӨәеҮәиүҜеҘҪзҡ„дәәж°”
- е…¬жј”|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢ第дә”ж¬Ўе…¬жј”зҺ°еңәпјҢжқҺж–Ҝдё№еҰ®з»„гҖҠжғ…дәәгҖӢеӨӘжғҠиүі
- зјәдҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- ж—¶е°ҡзӢӮжғіжӣІ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еҲ¶еӣўз»јпјҢеј йӣЁз»®з«ҷпјЈдҪҚпјҢз®ҖзәҰиЎ¬иЎЈзҪ•и§Ғз§ҖзҹҘжҖ§
- еҪ’дҪҚ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢпјҢйқ’жҳҘд»ҺжқҘдёҚзјәдҪҚпјҢд№ҹдёҚи®©дҪҚпјҢиҖҢжҳҜиҮӘдҝЎеҪ’дҪҚ
- 10жңҲ|еҚ°еәҰеҸ‘з”ҹ5.1зә§ең°йңҮпјҢйңҮжәҗж·ұеәҰ40еҚғзұі
- йҷҲиө«|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢжҲҗеӣўеӨңиҜ·дәҶ17дҪҚз”·еҳүе®ҫпјҢйҷҲиө«жғ№жқҘдёҖзүҮдәүи®®
- иҠӮзӣ®з»„|еӯҹдҪіпјҢеҲ«жҢЈжүҺдәҶпјҢгҖҠд№ҳйЈҺз ҙжөӘгҖӢиҠӮзӣ®з»„жҳҺж‘ҶзқҖжғіжҠҠдҪ ж·ҳжұ°
- е®Ғйқҷ|гҖҠд№ҳйЈҺз ҙжөӘзҡ„е§җе§җгҖӢеҪ•еӣўз»јпјҢе®ҒйқҷдёҮиҢңз ҙдёҚе’Ңдј й—»пјҢи·Ҝжј”и§Ҷйў‘ж¬ўд№җеӨҡ
- ж¶ҲжҒҜиө„и®Ҝ|д№ҳйЈҺз ҙжөӘ | еҸҳйқ©иҪ¬еһӢпјҡдәәжүҚеҹ№е…»вҖ”вҖ”дјҒдёҡиҪ¬еһӢдёҺеҲӣж–°зҡ„ж ёеҝғй©ұеҠЁеҠӣ